É possível personalizar e configurar a especificação do modelo de base do Meridian para suas necessidades, como adequar as distribuições a priori de ROI, ajustar a sazonalidade, definir a duração máxima de transferência, usar alcance e frequência e muito mais. Para mais informações, consulte a seção O modelo do Meridian.
Especificação do modelo padrão
Use estas especificações para começar a criar seu modelo:
model_spec = spec.ModelSpec(
prior=prior_distribution.PriorDistribution(),
media_effects_dist='log_normal',
hill_before_adstock=False,
max_lag=8,
unique_sigma_for_each_geo=False,
media_prior_type='roi',
roi_calibration_period=None,
rf_prior_type='roi',
rf_roi_calibration_period=None,
organic_media_prior_type='contribution',
organic_rf_prior_type='contribution',
non_media_treatments_prior_type='contribution',
knots=None,
baseline_geo=None,
holdout_id=None,
control_population_scaling_id=None,
)
Definir as distribuições a priori
É possível personalizar as distribuições na especificação do modelo padrão. Cada parâmetro recebe sua própria distribuição a priori independente, que pode ser definida pelo argumento prior no ModelSpec do Meridian. Consulte Distribuições a priori padrão para mais informações e exceções.
No exemplo de personalização a seguir, as distribuições a priori de ROI para os canais de mídia são diferentes.
- Canal 1:
LogNormal(0.2, 0.7) - Canal 2:
LogNormal(0.3, 0.9) - Canal 3:
LogNormal(0.4, 0.6) - Canal 4:
LogNormal(0.3, 0.7) - Canal 5:
LogNormal(0.3, 0.6) - Canal 6:
LogNormal(0.4, 0.5)
my_input_data = input_data.InputData( ... )
build_media_channel_args = my_input_data.get_paid_media_channels_argument_builder()
# Assuming Channel1,...,Channel6 are all media channels.
roi_m = build_media_channel_args(
Channel1=(0.2, 0.7),
Channel2=(0.3, 0.9),
Channel3=(0.4, 0.6),
Channel4=(0.3, 0.7),
Channel5=(0.3, 0.6),
Channel6=(0.4, 0.5),
) # This creates a list of channel-ordered (mu, sigma) tuples.
roi_m_mu, roi_m_sigma = zip(*roi_m)
prior = prior_distribution.PriorDistribution(
roi_m=tfp.distributions.LogNormal(
roi_m_mu, roi_m_sigma, name=constants.ROI_M
)
)
model_spec = spec.ModelSpec(prior=prior)
Em que prior em ModelSpec é um objeto PriorDistribution que especifica a distribuição a priori de cada conjunto de parâmetros do modelo. Os parâmetros recebem distribuições independentes que podem ser definidas pelo construtor prior_distribution.PriorDistribution().
Os parâmetros do modelo com um subscrito m (por exemplo, roi_m) podem ter o mesmo número de dimensões e canais de mídia ou apenas uma.
No primeiro caso, a ordem dos valores de parâmetro na distribuição a priori personalizada corresponde à ordem em data.media_channel. Isso significa que uma distribuição é configurada para cada canal de mídia. Se não for possível determinar uma distribuição personalizada para alguns dos canais, use manualmente o padrão tfd.LogNormal(0.2, 0.9). Quando uma distribuição a priori unidimensional é transmitida, ela é usada para todos os canais de mídia.
A lógica ao definir distribuições a priori para parâmetros de modelo com um subscrito c (por exemplo, gamma_c) é a mesma do subscrito m. Nos subscritos c, a quantidade de dimensões pode ser igual ao número de variáveis de controle ou ser apenas uma. No primeiro caso, a ordem dos valores de parâmetro na distribuição a priori personalizada corresponde à ordem em data.control_variable. Isso significa que uma distribuição é configurada para cada variável de controle.
No exemplo a seguir, um único número é usado para definir a distribuição a priori de ROI para os canais de mídia, ou seja, as distribuições nos dois canais são iguais, representadas como LogNormal(0.2, 0.9).
roi_mu = 0.2
roi_sigma = 0.9
prior = prior_distribution.PriorDistribution(
roi_m=tfp.distributions.LogNormal(roi_mu, roi_sigma, name=constants.ROI_M)
)
model_spec = spec.ModelSpec(prior=prior)
O Meridian tem um parâmetro de ROI (roi_rf) e um Beta (beta_rf) distintos para os canais que têm alcance e frequência. Por isso, algumas modificações são necessárias nos snippets de código já mencionados quando canais específicos têm dados de alcance e frequência. Neste exemplo, os canais 4 e 5 têm esses dados.
Para personalizar as distribuições a priori de ROI de cada canal de mídia:
# ROI prior for channels without R&F data build_media_channel_args = my_input_data.get_paid_media_channels_argument_builder() roi_m = build_media_channel_args( Channel1=(0.2, 0.7), Channel2=(0.3, 0.9), Channel3=(0.4, 0.6), Channel4=(0.3, 0.7), ) roi_m_mu, roi_m_sigma = zip(*roi_m) # ROI prior for channels with R&F data build_rf_channel_args = my_input_data.get_paid_rf_channels_argument_builder() roi_rf = build_rf_channel_args( Channel5=(0.3, 0.6), Channel6=(0.4, 0.5), ] roi_rf_mu, roi_rf_sigma = zip(*roi_rf) prior = prior_distribution.PriorDistribution( roi_m=tfp.distributions.LogNormal( roi_m_mu, roi_m_sigma, name=constants.ROI_M ), roi_rf=tfp.distributions.LogNormal( roi_rf_mu, roi_rf_sigma, name=constants.ROI_RF ), ) model_spec = spec.ModelSpec(prior=prior)
A ordem dos valores de parâmetro em roi_rf_mu e roi_rf_sigma precisa ser igual a data.rf_channel.
Para definir as mesmas distribuições em todos os canais de mídia:
roi_mu = 0.2 roi_sigma = 0.9 prior = prior_distribution.PriorDistribution( roi_m=tfp.distributions.LogNormal( roi_mu, roi_sigma, name=constants.ROI_M), roi_rf=tfp.distributions.LogNormal( roi_mu, roi_sigma, name=constants.ROI_RF ), ) model_spec = spec.ModelSpec(prior=prior)
Usar uma divisão de dados de treinamento e teste (opcional)
Recomendamos usar uma divisão para evitar o overfitting e garantir a generalização do modelo com novos dados. Isso pode ser feito usando holdout_id. Essa etapa é opcional.
O exemplo a seguir mostra um argumento holdout_id que define aleatoriamente 20% dos dados como o grupo de teste:
np.random.seed(1)
test_pct = 0.2 # 20% of data are held out
n_geos = len(data.geo)
n_times = len(data.time)
holdout_id = np.full([n_geos, n_times], False)
for i in range(n_geos):
holdout_id[
i,
np.random.choice(
n_times,
int(np.round(test_pct * n_times)),
)
] = True
model_spec = spec.ModelSpec(holdout_id=holdout_id)
Em que holdout_id é um tensor booleano opcional de dimensões (n_geos x n_times) ou (n_times) que indica quais observações são excluídas da amostra de treinamento. Apenas a variável de resposta é excluída da amostra de treinamento. As de mídia são incluídas porque podem afetar o Adstock das semanas seguintes. Padrão: None, o que significa que não há regiões geográficas e tempos de validação.
Adaptar o ajuste periódico automático (opcional)
O Meridian aplica o ajuste periódico automático usando uma abordagem de interceptação que varia com o tempo. Mude o valor de knots para ajustar os efeitos.
Para mais informações, consulte Como o argumento knots funciona.
knots é um número inteiro ou uma lista de números inteiros (opcional) que indica os nós usados para estimar os efeitos do tempo. Quando knots é uma lista, ela fornece o locais dos nós. "Zero" corresponde a um nó no primeiro período, "um" a um nó no segundo período de tempo e assim por diante, com (n_times - 1) correspondendo a um nó no último período.
Quando knots é um número inteiro, há um número correspondente de nós com localizações igualmente espaçadas nos períodos, incluindo nós em "zero" e (n_times - 1). Quando knots é 1, há um único coeficiente de regressão comum usado para todos os períodos.
Se knots for definido como None, o número de nós usados e de períodos será igual, no caso de um modelo geográfico. Isso equivalente a cada período ter seu próprio coeficiente de regressão. Para modelos nacionais, se knots for definido como None, o número de nós usados será 1. Por padrão, o valor é definido como None.
Para mais informações, consulte Como escolher o número de nós para efeitos temporais no modelo.
Exemplos
Definir
knotscomo1para não ter ajuste periódico automático. Nesse caso, recomendamos incluir seus próprios valores de sazonalidade ou feriados como variáveis de controle:model_spec = spec.ModelSpec(knots=1)Definir
knotscomo um número relativamente grande:knots = round(0.8 * n_times) model_spec = spec.ModelSpec(knots=knots)Definir nós para cada quatro pontos de tempo:
knots = np.arange(0, n_times, 4).tolist() model_spec = spec.ModelSpec(knots=knots)Definir um nó em novembro e outro em dezembro, e os demais relativamente esparsos. Para tornar este exemplo mais simples, suponha que há apenas 12 pontos de dados e que os dados são mensais (essa premissa não é realista nem recomendada). Confira na tabela a seguir:
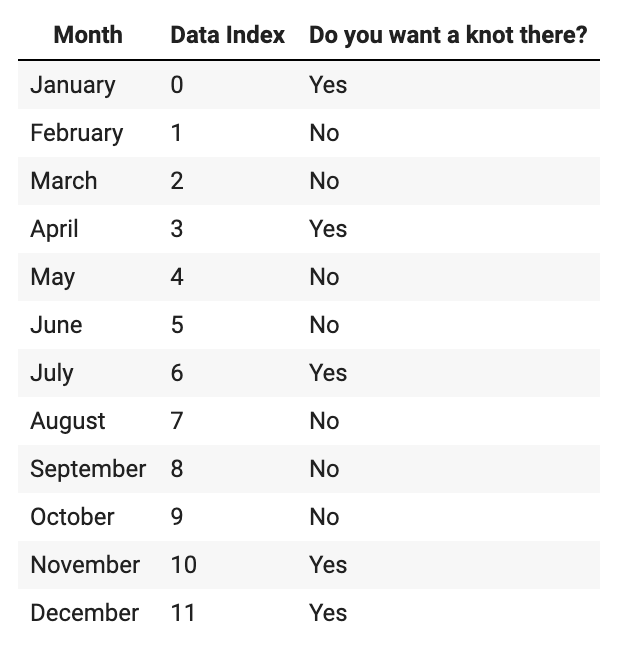
Para definir nós nos índices
0,3,6,10e11:knots = [0, 3, 6, 10, 11] model_spec = spec.ModelSpec(knots=knots)
Você pode usar uma abordagem semelhante para garantir a disponibilidade nos principais feriados.
Ajustar a calibragem do ROI (opcional)
O Meridian apresenta um método que redefine o ROI como um parâmetro do modelo. Para mais informações, consulte Distribuições a priori de ROI para calibragem.
Por padrão, a mesma distribuição não informativa do ROI é aplicada a todos os canais de mídia. Para ajustar esse recurso, siga um destes procedimentos:
- Desativar a calibragem do ROI
- Definir o período de calibragem do ROI
Desativar a calibragem do ROI
É possível desativar o recurso de calibragem do ROI usando media_prior_type='coefficient' e rf_prior_type='coefficient':
model_spec = spec.ModelSpec(
media_prior_type='coefficient',
rf_prior_type='coefficient',
)
O argumento media_prior_type indica se é necessário usar uma distribuição a priori em roi_m, mroi_m ou beta_m na PriorDistribution. Padrão: 'roi'
(recomendado)
Definir o período de calibragem do ROI
Embora os coeficientes de regressão do efeito de mídia não tenham efeitos que variam com o tempo, há um argumento de janela de calibragem para definir a distribuição a priori do ROI (ou mROI). Isso ocorre porque o ROI (ou mROI) em um determinado momento depende de outros fatores que podem variar com o tempo:
- Como as curvas de Hill modelam os retornos não lineares e decrescentes da execução de mídia, a quantidade de execuções pode afetar o ROI.
- Alocação de mídia em regiões geográficas com eficácias diferentes.
- Custo da execução de mídia.
É possível calibrar a MMM usando um subconjunto de dados quando os resultados experimentais não refletem o retorno do investimento em publicidade (ROAS) do modelo que ela pretende medir. Por exemplo, o período do experimento e dos dados da MMM não estão alinhados. Para mais informações, consulte Calibragem do modelo de mix de mídia com distribuições a priori bayesianas (em inglês) e Calibragem e distribuições a priori de ROI.
O exemplo a seguir mostra como especificar o período de calibragem do ROI de '2021-11-01' para '2021-12-20' no canal 1. Os canais de mídia não especificados no roi_period vão usar todos os períodos disponíveis para a calibragem do ROI.
roi_period = {
'Channel1': [
'2021-11-01',
'2021-11-08',
'2021-11-15',
'2021-11-22',
'2021-11-29',
'2021-12-06',
'2021-12-13',
'2021-12-20',
],
}
roi_calibration_period = np.zeros((len(data.time), len(data.media_channel)))
for i in roi_period.items():
roi_calibration_period[
np.isin(data.time.values, i[1]), data.media_channel.values == i[0]
] = 1
roi_calibration_period[
:, ~np.isin(data.media_channel.values, list(roi_period.keys()))
] = 1
model_spec = spec.ModelSpec(roi_calibration_period=roi_calibration_period)
Neste caso, roi_calibration_period é uma matriz booleana opcional com o formato (n_media_times, n_media_channels), indicando o subconjunto de time para a calibragem do ROI da mídia. Se definido como None, todos os valores serão usados para a calibragem.
Padrão: None.
O Meridian tem um parâmetro diferente, rf_roi_calibration_period, para os canais com alcance e frequência.
O exemplo a seguir mostra como especificar o período de calibragem do ROI de '2021-11-01' para '2021-12-20' no canal 5, que usa alcance e frequência como entradas.
roi_period = {
'Channel5': [
'2021-11-01',
'2021-11-08',
'2021-11-15',
'2021-11-22',
'2021-11-29',
'2021-12-06',
'2021-12-13',
'2021-12-20',
],
}
rf_roi_calibration_period = np.zeros(len(data.time), len(data.rf_channel))
for i in roi_period.items():
rf_roi_calibration_period[
np.isin(data.time.values, i[1]), data.rf_channel.values == i[0]
] = 1
rf_roi_calibration_period[
:, ~np.isin(data.rf_channel.values, list(roi_period.keys()))
] = 1
model_spec = spec.ModelSpec(rf_roi_calibration_period=rf_roi_calibration_period)
Em que rf_roi_calibration_period é uma matriz booleana opcional de formato (n_media_times, n_rf_channels). Se definido como None, todos os tempos e regiões serão usados para a calibragem.
Padrão: None.
Definir outros atributos (opcional)
Você pode mudar os demais atributos na especificação do modelo padrão conforme necessário. Esta seção descreve esses atributos e exemplos de como mudar os valores.
baseline_geo
Um número inteiro ou uma string (opcional) para a região de base. Ela é tratada como a região geográfica de referência na codificação fictícia de regiões. As demais regiões têm uma variável de indicador tau_g correspondente e uma variância de distribuição a priori maior que a região de base. Quando definida como None, a região com a maior população é usada como base. Padrão: None
O exemplo a seguir mostra a região de base definida como 'Geo10':
model_spec = spec.ModelSpec(baseline_geo='Geo10')
hill_before_adstock
Um booleano que indica se a função de Hill deve ser aplicada antes da Adstock, em vez da ordem padrão Adstock e depois Hill. Padrão: False
Os exemplos a seguir mostram que a função de Hill será aplicada primeiro, definindo o valor como True:
model_spec = spec.ModelSpec(hill_before_adstock=True)
max_lag
Um número inteiro que indica o número máximo de períodos de atraso (>= 0) a serem incluídos no cálculo de Adstock. Também pode ser definido como None, que equivale a todo o período de modelagem. Padrão: 8
O exemplo a seguir muda o valor para 4:
model_spec = spec.ModelSpec(max_lag=4)
media_effects_dist
Uma string que especifica a distribuição de efeitos aleatórios de mídia em regiões geográficas.
Valores permitidos: 'normal' ou 'log_normal'. Padrão: 'log_normal'
Em que:
media_effects_dist='log_normal'é \(\beta m,g\ {_\sim^{iid}} Lognormal(\beta m, \eta ^2m)\)media_effects_dist='normal'é \(\beta m,g\ {_\sim^{iid}} Normal (\beta m, \eta ^2m)\)
O exemplo a seguir mostra como mudar o valor para 'normal':
model_spec = spec.ModelSpec(media_effects_dist='normal')
control_population_scaling_id
Um tensor booleano opcional de dimensão (n_controls) que indica para quais variáveis de controle o valor de controle será ajustado pela população. Padrão: None
O exemplo a seguir especifica que a variável de controle no índice 1 será dimensionada pela população:
control_population_scaling_id = np.full([n_controls], False)
control_population_scaling_id[1] = True
model_spec = spec.ModelSpec(
control_population_scaling_id=control_population_scaling_id
)
unique_sigma_for_each_geo
Um booleano que indica se é necessário usar uma variância residual exclusiva para cada região. Se for False, uma única variância residual será usada para todas as regiões. Padrão: False
O exemplo a seguir define o modelo para usar uma variância residual exclusiva para cada região:
model_spec = spec.ModelSpec(unique_sigma_for_each_geo=True)